
第三章—程序的机器级表示
3.2 程序编码
机器级代码
这里有一些跟我平常看到不一样的名词
- 程序计数器(之前一直都叫它ip, 就是给出指令地址的寄存器): 通常称为PC, 给出下一条指令的地址
- 条件码寄存器: 保存最近执行的算数或逻辑指令的状态信息, 实现if和while语句(汇编里的jnz, 看的就是这个)
ATT与Intel汇编代码格式
- ATT是运营贝尔实验室的公司的汇编代码格式, 是GCC, OBJDUMP和其他工具使用的格式 :如: mov rbx, rdx 是将rbx的值给rdx
- Intel是我们平常看见的格式 :如: mov rbx, rdx 是将rdx的值给rbx, 跟上面的格式是反过来的, (两者有点像大小端)
3.3 数据格式
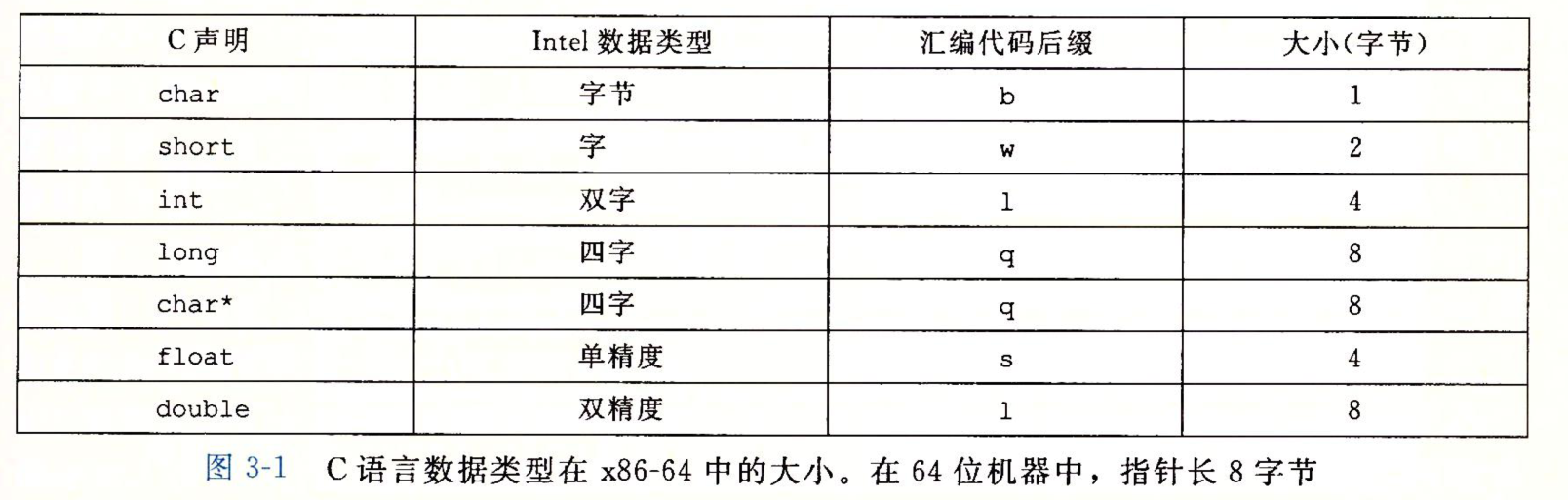
GCC生成的汇编代码都有一个字符的后缀表明操作数的大小
- movb 传送字节
- movw 传送字
- movl 传送双字
- movq 传送四字
浮点数也有s 跟 l, 但跟整数不会产生冲突, 因为寄存器不一样, 可以根据寄存器来进行判断
3.4 访问信息
寄存器
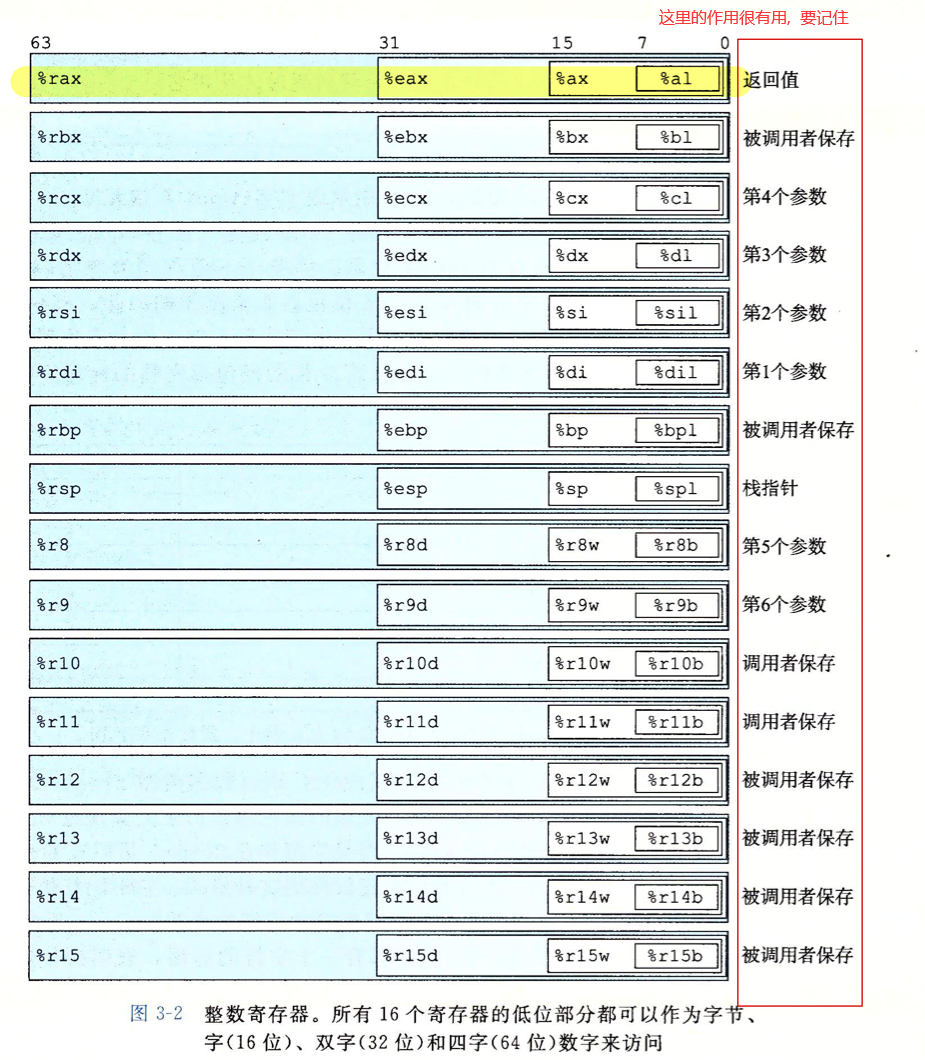
寄存器处理各种长度的数据的方案
- 1字节&2字节: 保持剩下的字节数不变
- 四字节: 会把高四位的四个字节置为 0
操作数指示符
大多数指令都有一个或者多个操作数(注意是大多数, 也就是说存在没有操作数的指令)
操作数分为三种类型:
- 立即数: (在ATT格式汇编中)书写方式是 ’ $ ’ 后跟常数值, 如: $ -577 和 $ 0x1F
- 寄存器: 表示每个寄存器的内容, 一个寄存器也分为1字节, 2字节, 4字节, 8字节 .其中r来表示任意寄存器, R[r] 来表示r寄存器的值
- 内存引用: Addr表示地址, M[Addr]表示对存储在内存中从Addr开始的引用
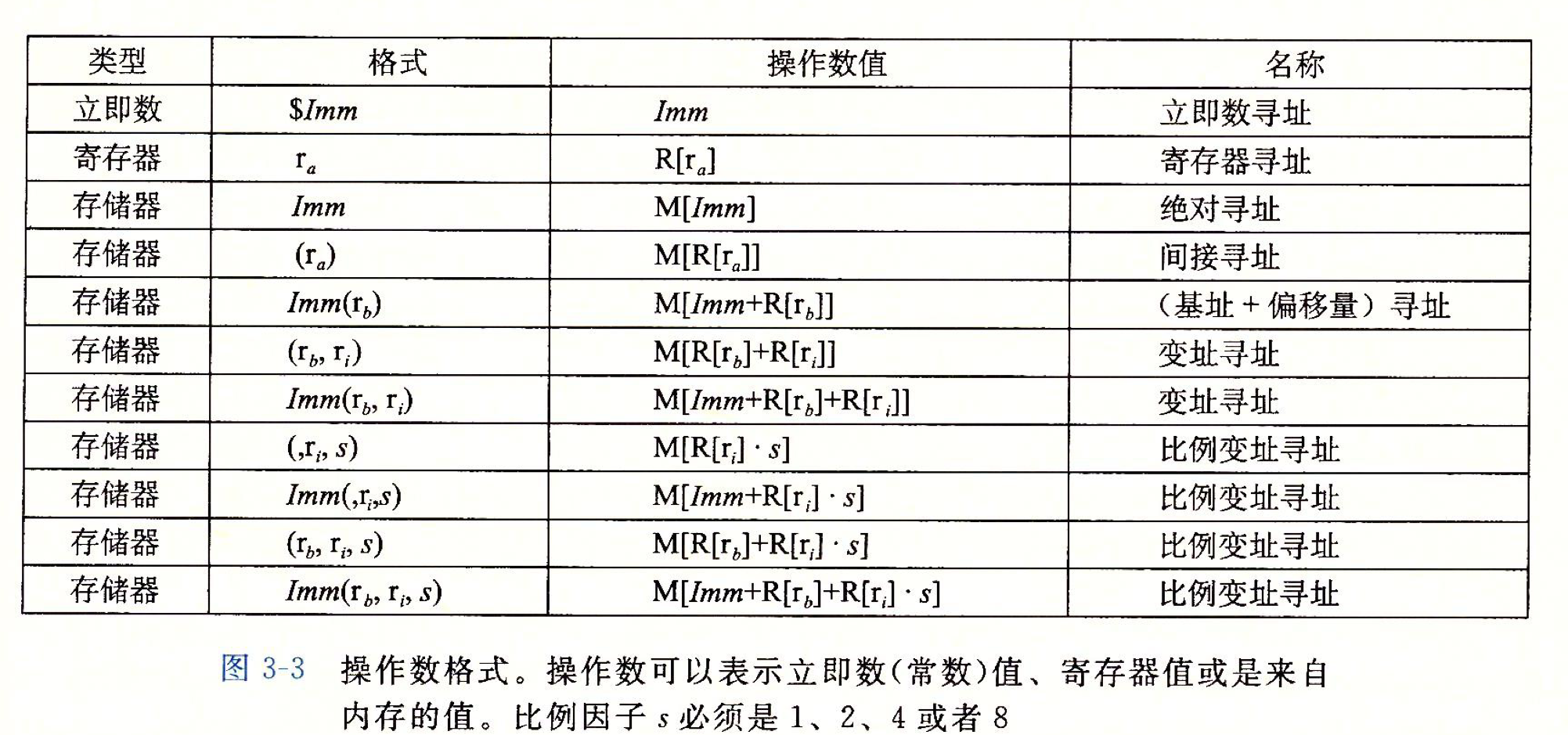
上面的这张图还是背下来比较好, 还有注意图下的话, 比例因子s必须是1, 2, 4 和 8
记住上面的要领就是, 只有$ 和 RXX(寄存器) 这两个表示的是直接数, 其他都表示的是地址(当然, 也要看具体的指令, 比如lea)
数据传送指令
MOV类
主要讲的是MOV类, 分为以下类:
- movb 传送1字节数据(字节)
- movw 传送2字节数据(字)
- movl 传送4字节数据(双字), 其他赋值给寄存器的mov都不会改变寄存器其他的位, 但是movl会把寄存器高位的4字节设置为0
- movq 传送8字节数据(四字)
- 重点: mov指令的两个操作数不能都指向内存位置(之前汇编语言也讲过, 我觉得这个真的很重要) 所以我们要将一个内存a的值写入内存b中, 要先将a中的值给寄存器, 然后寄存器再将值写入内存b中
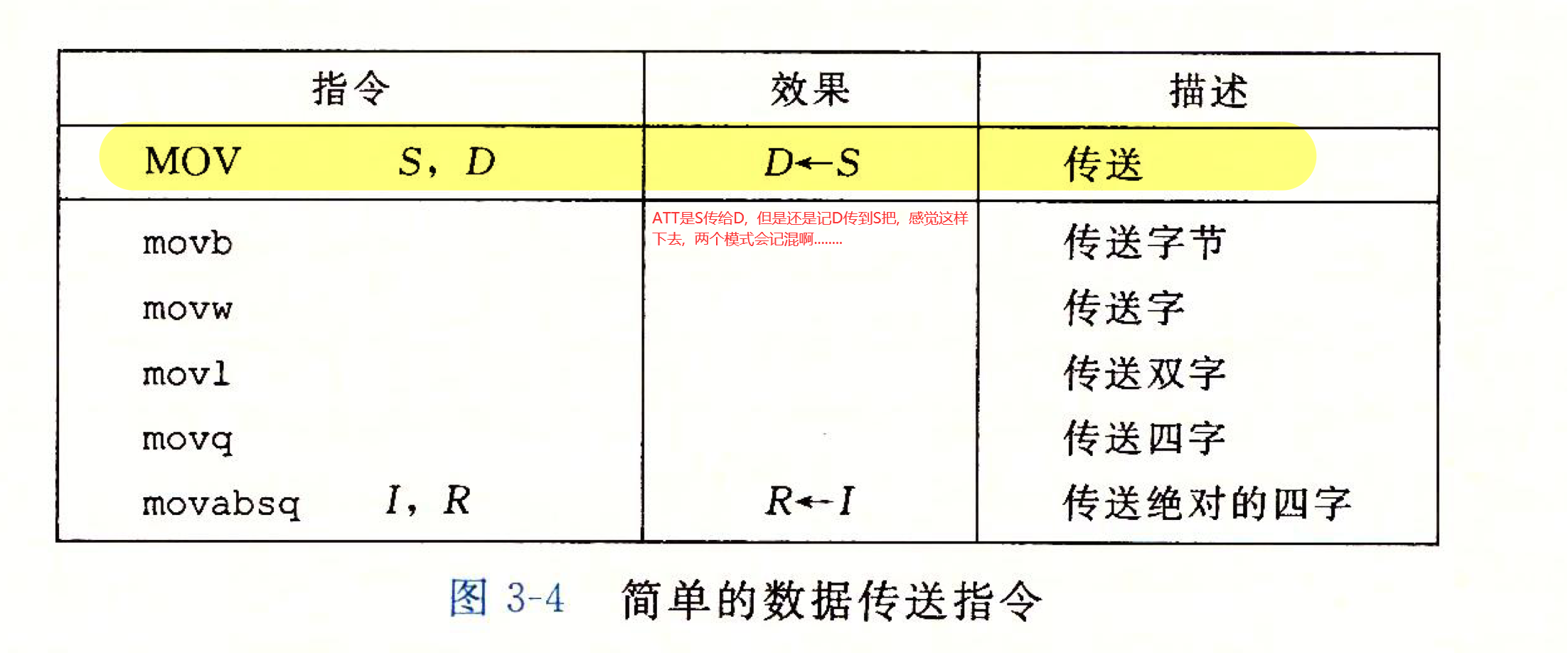
movabsq传送绝对的四字就是传送的值一定是长度位64位.
这里讲一下mavq和movabs的区别:
- 如果源操作数是立即数的话没有区别
- 64位编译下, 源操作数如果是标号, 默写情况下只能用movabs进行64位立即数的赋值而无法使用movq
MOVZ(Z就是zero, 意思是零扩展)类:
- movzbw b → w 将做了零扩展的字节传送到字
- movzbl b → l 将做了零扩展的字节传送到双字
- movzwl w → l 将做了零扩展的字传送到双字
- movzbq b → q 将做了零扩展的字节传送到四字
- movzwq w → q 将做了零扩展的字传送到四字
注意零扩展是用零填充到目的操作数的长度, 其次源操作数的长度必须小于目的操作数(要不然也没意义)
MOVS(S就是sign, 意思是符号扩展)类:
- movsbw b → w 将做了零扩展的字节传送到字
- movsbl b → l 将做了零扩展的字节传送到双字
- movswl w → l 将做了零扩展的字传送到双字
- movsbq b → q 将做了零扩展的字节传送到四字
- movswq w → q 将做了零扩展的字传送到四字
- movslq l → q 将做了符号扩展的双字传送到四字(注意上面是没有这一条的, 因为原本l到q就会做高四字节的零填充)
- cltq 符号扩展(%eax) → %rax 把%eax符号扩展到%rax, 相当于movslq %eax, %rax
注意: 符号扩展的符号看源操作数, 扩展的范围看目的操作数.
压入和弹出数据
栈是一种数据结构, 遵循”后进先出”的原则, 在过程调用中起到至关重要的作用.
压入和弹出的具体过程:
压入:
- 栈顶指针向低地址移动
- 将数据压入栈中
弹出:
- 将数据弹出
- 栈顶指针向高地址移动
可以看到上面压入和弹出的顺序是相反的, 其实把这个过程想成一个桶, 你要先腾出空间才能放进东西, 同理, 你也要先把东西拿出来, 才能压缩空间(这样记会好记一些).
算术和逻辑操作
大多数操作都分成了指令类, 指令类又不同大小操作数的变种(leaq除外仅此一个):
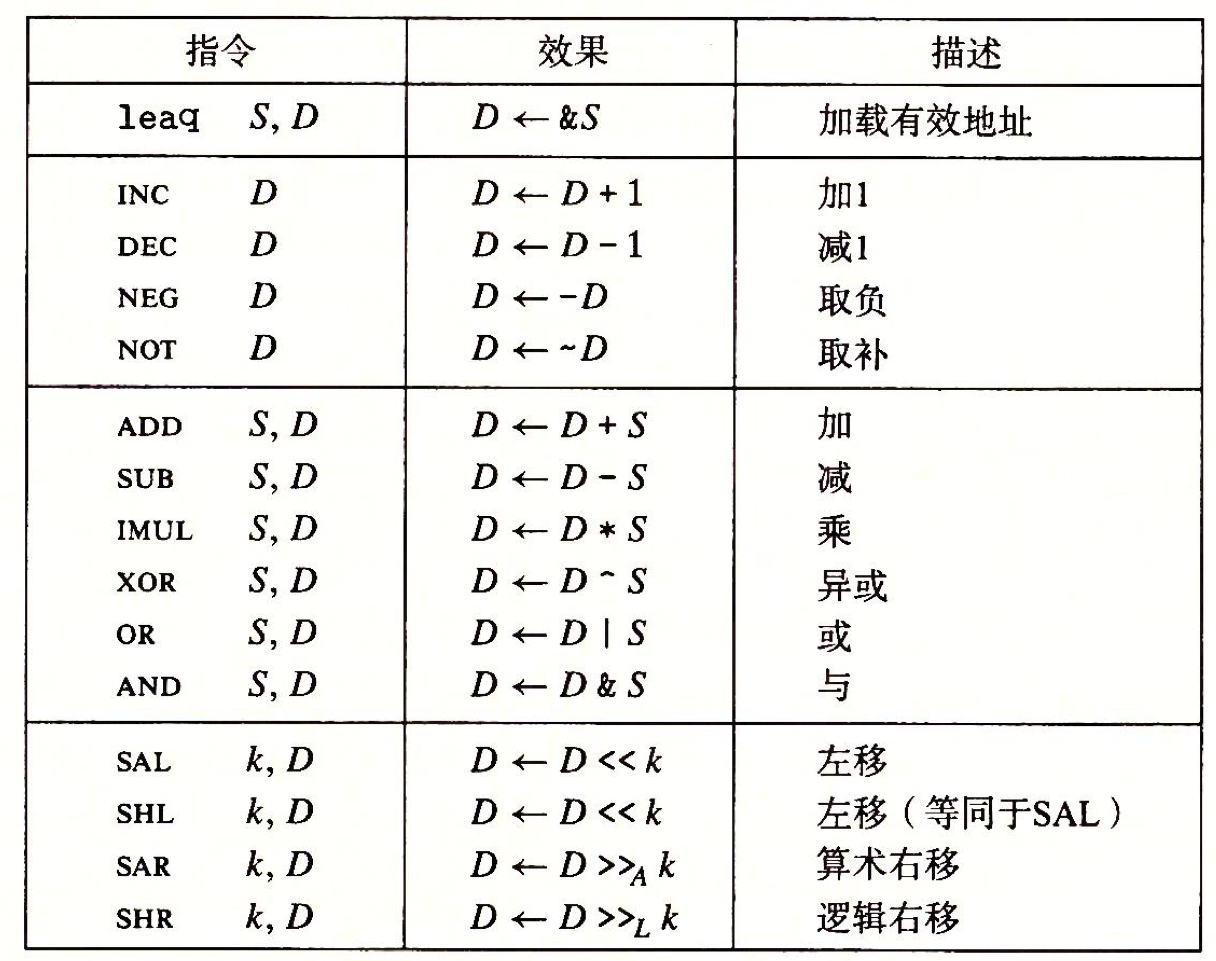
注意看操作数运算的顺序, 然后学个新词(arithmetic 算术)
加载有效地址—leaq(load effective address)
功能有两个:
- 将有效的内存地址传给目的操作数
- 进行简介的算术操作, 比如: leaq 7(%rdx, %rdx, 4), %rax, 设 rdx 为 x 就是5x + 7
一元和二元操作
一元操作是只有一个操作数(既是源也是目的), 比如: inc(加一), dec(减一)
二元操作是有两个操作数, 其中第三组的第二个操作数既是源也是目的, 不过要记住源操作数是第一个, 目的操作数是第二个(这段话来自书中, 说实话有点看不懂, 但是我觉得知道第三组各个指令的用法和含义就好了, 在这里不用深究)
移位操作
左移操作
又SAL 和 SHL, 二者作用一样, 因为左移不用考虑符号的问题, 全部补零即可
右移操作
- SAR(arithmetic)算术右移, 适用补码, 根据最高符号位决定填充为 0 还是 1
- SHR(逻辑不是logic吗)逻辑右移, 适应无符号类型, 填充始终为 0
特殊的算术操作
两个64位整数相乘得到的乘积需要128位(两个64位寄存器)来表示, 将其称为16个字节的八字(oct word)

多出来的部分就用RDX来表示
操作数可以是两个也可以是一个, 一个时, 那个操作数就是源操作数, 而目的操作数则在%RAX中
虽然用的时同一个指令, 但汇编器能够通过操作数个数来判断你想要表达什么.
除法运算
- 对于128位除法运算(idivl), 高64位放在RDX, 低64位放在RAX, 然后使用idivl num, 相当于 RDXRAX / num , 商会存储在RAX中, 余数则存储在RDX中
- 对于64位除法运算(idivq), 被除数放在RAX中, 然后使用idivq num, 相当于RAX / num 商存储在RAX中, 余数存储在RDX中
- 注意使用前要先使用cqto(ATT格式)或者cqo(intel格式)将rdx的位设为0(无符号)或rax的符号位(补码)
还是用书中的实例更清晰一些


控制
直线代码: 就是指令一条接着一条顺序执行.
但是条件语句, 循环语句, 分支语句, 要根据测试结果来决定程序操作执行的顺序, 这时我们就需要机器代码提供的两种基本的低级机制来实现有条件的行为, 也就是: 测试数据值, 然后根据测试的结果来改变控制流或者数据流. 一个就是jump.
条件码
条件码(condition code)寄存器: 描述了最近的算术或逻辑操作的属性, 可以通过条件码的值来执行条件分支指令.
常见的条件码:
- CF (carry flag): 进位标志, 最近的操作使最高位产生进位, 可用于检查无符号操作的溢出
- ZF (zero flag): 零标志, 最近的操作得出的结果为0, 则flag为 1 .
- SF (sign flag): 符号标志, 最近的操作得到的结果为负数, 则flag为 1 .
- OF (over flag): 溢出标志, 最近的操作导致一个补码溢出——正溢出或负溢出.
leaq不改变条件码, 因为它是用来进行地址运算的
一些规则:
- 对于逻辑操作, 如 xor , 进位和溢出标志都会设置为 0 , 因为逻辑操作不可能进位或者溢出
- 对于移位操作, 进位标志将设置为最后一个被移出的位, 而溢出标志设置为 0 .
- INC 和 DEC 指令会设置溢出和零标志, 但不会改变进位标志, 原因不深入讨论.
CMP 和 TEST 指令
只设置条件码寄存器, 而不改变其他寄存器的值
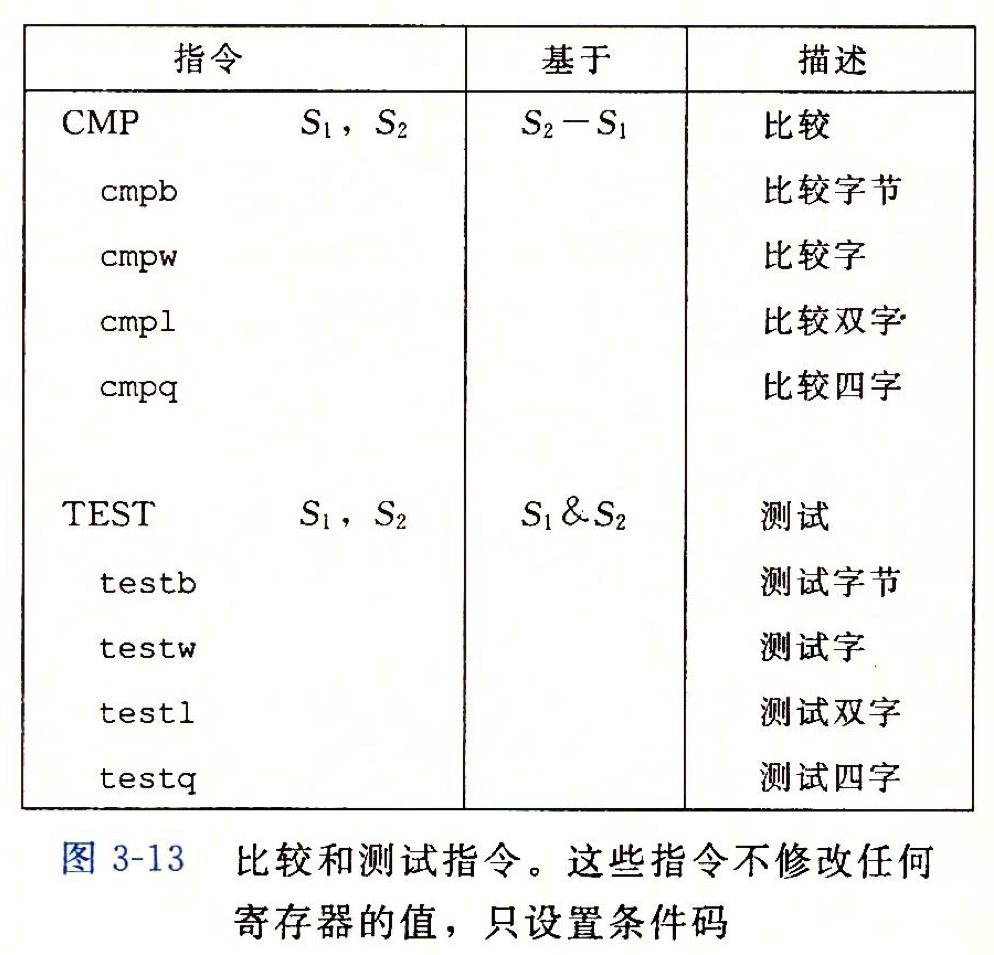
AT&T风格与Intel风格的cmp之间的差异(记得之前写过的, 但是没找着, 这里多写一遍, 如有重复, 不要忽略, 看两遍, 真的容易记混)
AT&T风格
1 | cmp %eax, %ebx |
Intel风格
1 | cmp %eax, %ebx |
访问条件码
使用方法有三种:
- 可以根据条件码的组合, 将一个字节(可以是寄存器的字节形式 ( 如al ) , 也可以是字节内存)设为0 或者1
- 可以条件跳转到程序的某个其他的部分
- 可以有条件的传送数据
第一种方法(SET)
将一个字节设置为 0 或者 1 , 我们将这类指令称为SET指令; 这些指令名字的不同后缀指明了它们所需要考虑的条件码的组合(而不代表大小).如:
- setl: 表示小于时设置( set less ), 而不是设置长字( set long word )
- setb: 表示低于时设置( set below ), 而不是设置字节( set byte )
这里重复上面的话: SET一个字节(可以是寄存器的字节形式 ( 如al ) , 也可以是字节内存)设为0 或者1但是有时我们会想要得到的是一个32位或者是64位的结果(也许是因为我们的变量设置为int), 我们必须对高位清零.
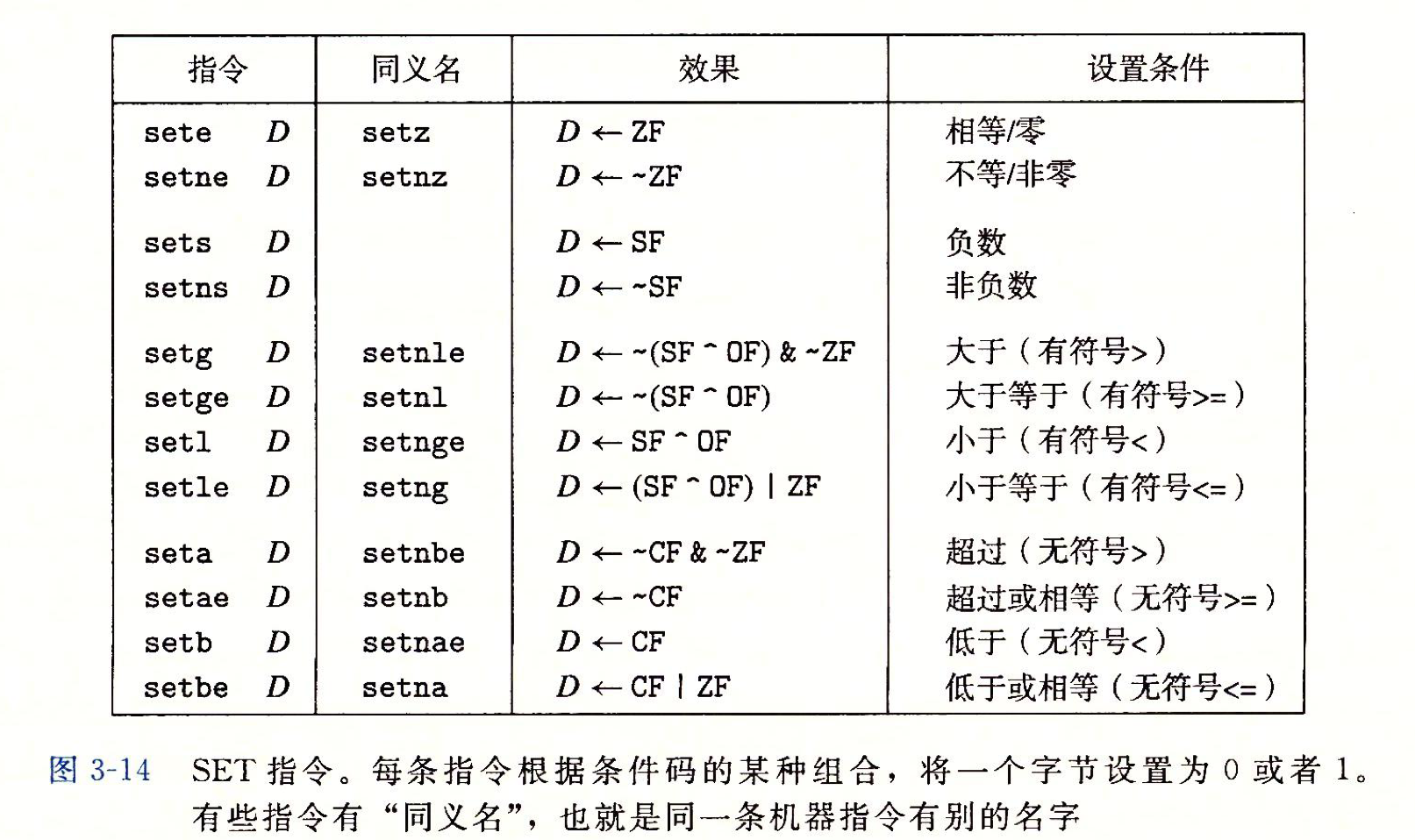
注意:
ATT的cmp指令是后面的减前面的, 所以小于表示的是, 第二个操作数小于第一个操作数
而Intel的cmp指令是前面的减后面的, 所以小于表示的是, 第一个操作数小于第二个操作数
不得不提CSAPP的ATT跟Intel风格的差异真的让人头晕, 看到这里真的麻了………
跳转指令
正常执行下, 指令是按照出现顺序一条一条的执行, 但是跳转指令( jmp )会导致执行切换到程序中一个全新的位置. 这些跳转的目的地通常用一个标号( label )指明.
跳转指令的目标
目标有三种类型:
- 直接跳转, 标号作为跳转的目标, 如: jmp .1L
- 间接跳转, 寄存器中的值作为跳转目标, 如: jmp *%rax, * 为操作数指示符
- 间接跳转, 内存中的值作为跳转目标, 如: jmp *(%rax), 用寄存器rax中的值作为地址, 从内存中读出跳转目标
跳转类型又分为两种:
- jmp, 无条件跳转
- jnz等, 有条件跳转
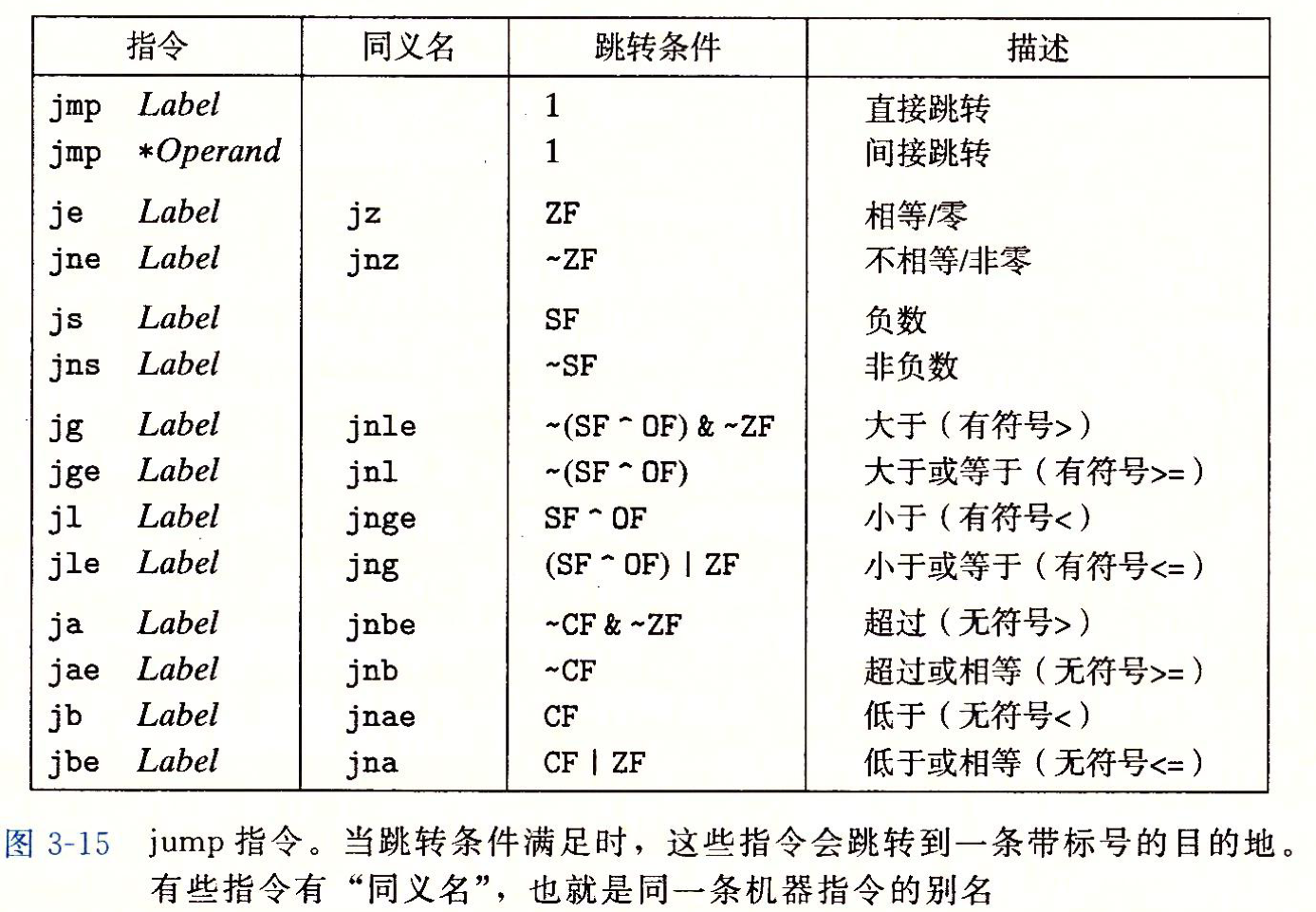
这里有一个记忆方法(比较捞): 带ab的是无符号的, gl是有符号的, e是不知道(只用记住ab就好了, 其他的可以排除法)
跳转指令的编码
汇编代码中, 跳转目标使用符号和标号书写, 汇编器, 以及链接器会产生跳转目标的编码, 主要的编码方式有两种:
- 最常用的是PC相对(PC-relative), 是将目标指令的地址与紧跟在跳转指令后的那条指令的地址之间的差作为编码.
- 第二种是给出”绝对”地址, 用四个字节直接指定目标
PC相对
看一下书中的例子

这样的编码方式可以保证指令编码的简介(只用两个字节, 如果用绝对地址就需要更长的编码了)
用条件控制来实现条件分支
常见的有cmp还有test跟jmp, jnz系列的组合来构成条件分支
看看书中的实例比较清晰

用条件传送来实现条件分支
先将两种情况的结果计算出来, 再根据判断决定谁是最终的结果
与条件控制不同的地方在于:
- 预先计算出了两个结果, 再判断
- 使用的是传送指令, 且传送指令受判断决定是否执行
在这里我还要再说一下第二个不同之处, 条件控制就像是一个空的盒子, 你判断后再决定放书还是放零食, 条件传送是原本装了零食了, 然后你判断是保持放零食不变, 还是把零食换成书

条件传送效率比条件控制高的原因
处理器通过使用流水线( pipelining )来获得高性能, 这里用自己的话来讲更容易一些: 就是处理器会预先处理前面的指令, 所以如果条件预判错误的话, 会损失性能. 然而条件传送则受到的影响很小.
下面是条件传送的种类:
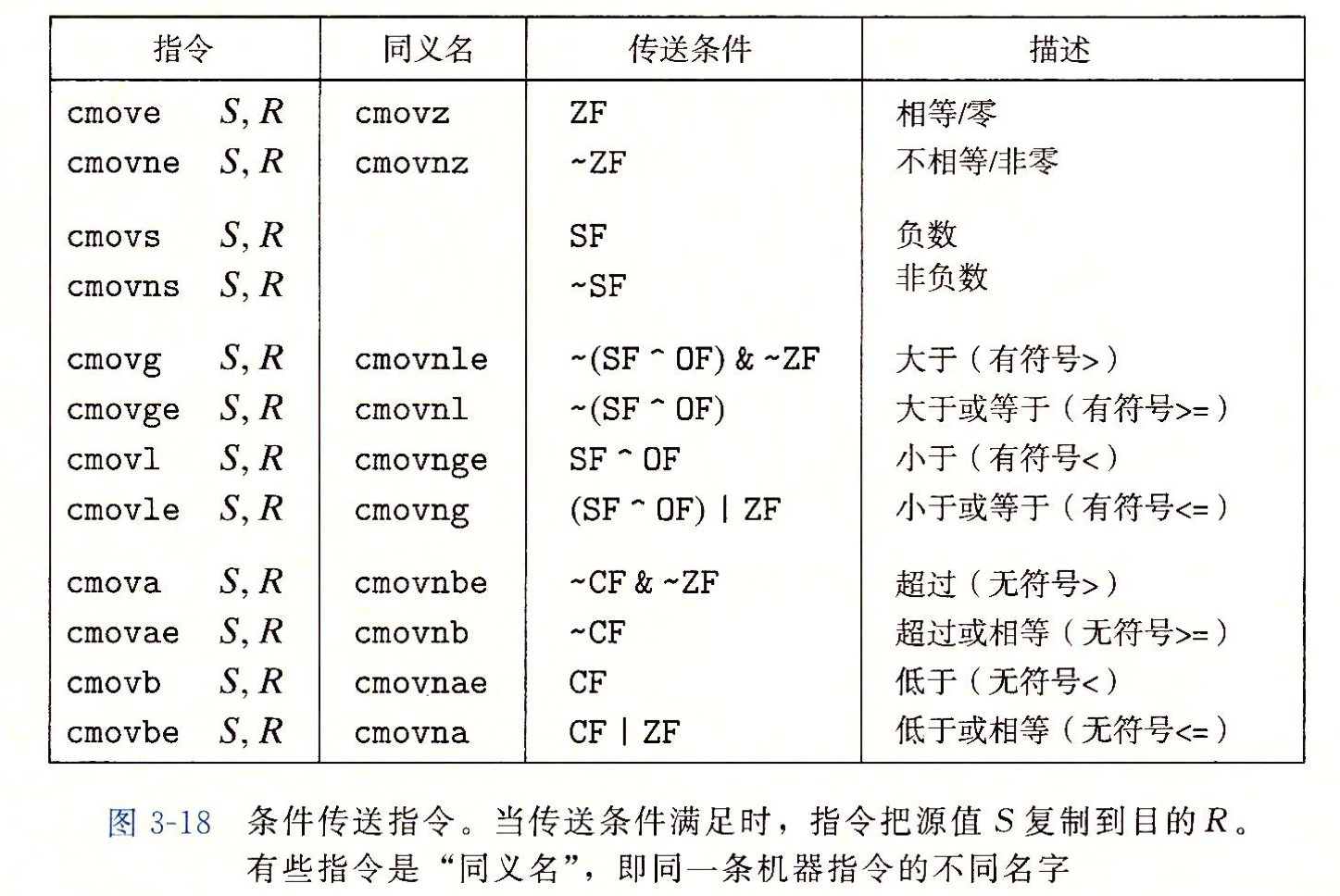
后缀变成了条件, 而关于数据长度则通过寄存器的类别判断
但是必须要注意, 条件传送的弊端:
- 两个结果的其中一个可能导致程序错误, 如果使用条件传送提前执行的话, 程序将无法运行
- 如果两个结果的运算过程都很复杂, 使提前计算所耗费的性能超过了条件控制的惩罚那就得不偿失了
所以虽然条件传送更符合现代处理器的运行方式, 但是它只能运行在非常受限的情况.
练习题3 . 20
这道题学到了关于除法和右移之间的关系

一开始的除法运算时猜的.
主要的疑问在于为什么要加上 7
这当公式被就行了
1 | 如果负数要右移k位, 那么用被除数的补码加上2 ^ k - 1(注意, ^表示的是次方的意思) |
循环
do-while, while 和 for再汇编中是通过条件测试和跳转组合起来实现循环的效果
do-while循环
模板
1 | loop: |
用书中的实例说明

while循环
实现while循环共有两种方法
- 方法一(跳到中间(jump to middle)): 使用一个无条件跳转, 直接跳转到检查条件处
模板
1 | goto test; |
书中实例:

- 方法二(guarded-do): 再循环前先使用条件分支, 不成立则跳过循环, 等于加上了单次的检查
模板:
1 | t = test-expr; |
书中实例:


for循环
for循环一般形式为
1 | for (init-expr; test-expr; update-expr) |
转换成while:
1 | init0expr; |
所以可以使用两个表示while的方式(jump to middle 和 guarded-do)来表示for循环
- jump to middle方法表示for循环
模板
1 | init-expr; |
- guarded-do方法表示for循环
模板
1 | init-expr; |
switch语句
通过跳转表(jump table)这种数据结果来实现更加高效的表现.
通过实例


过程
过程(函数就是其中一种)是软件中一种很重要的抽象. 提供了一种分装代码的方式, 用一组指定的参数和可选的返回值实现了某种功能. 然后, 可以在程序中不同的地方Dion公用这个过程.
形式多样:
- 函数(function)
- 方法(method)
- 子例程(subroutine)
- 处理函数(handler)
其中的调用机制(假设P调用了Q)
- 传递控制, 进入过程Q是, 程序计数器(rip)必须是Q代码的起始地址, 返回时程序计数器又必须是P调用Q的那条指令后面的地址
- 传递数据, P能向Q传递一个或多个参数, Q能向P返回一个值
- 分配和释放内存, 开始时给Q分配内存空间, 结束时释放内存空间
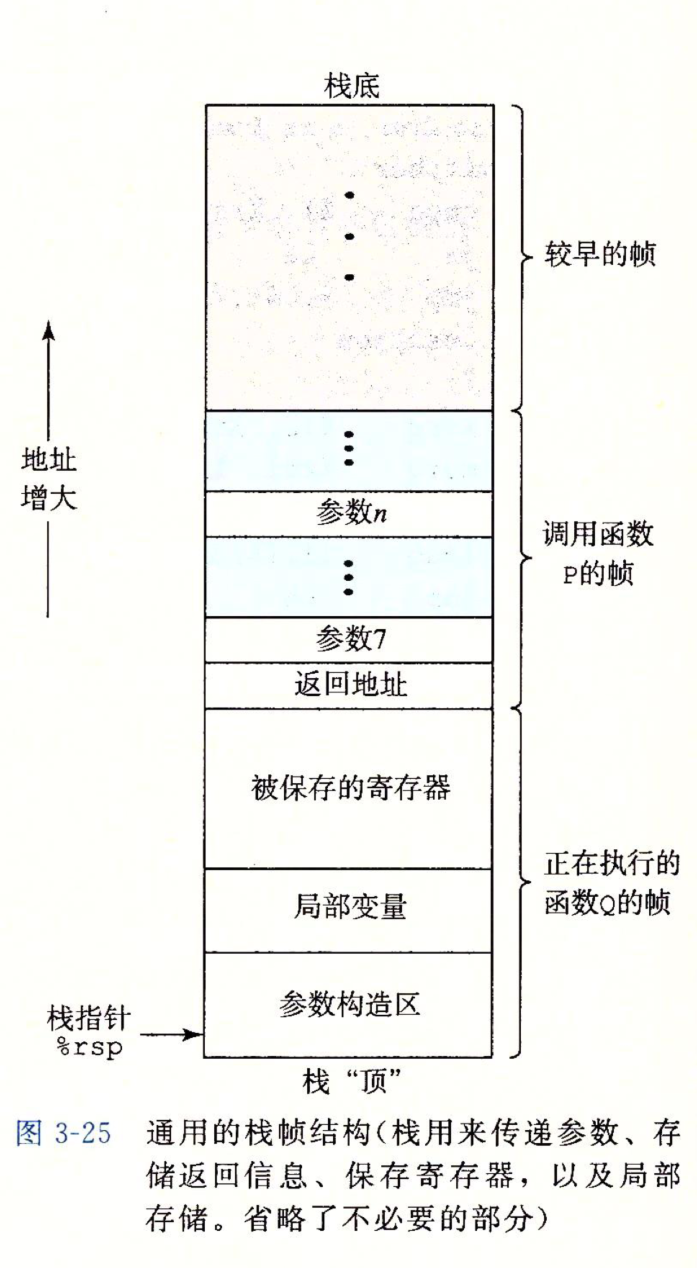
运行时栈
主要的图
转移控制
将控制从P转移到Q, 只用把程序计数器设置成Q的代码, 但是返回时需要P下条指令的代码, 这就需要我们的转移控制机制了(将P下条指令的地址保存备用)
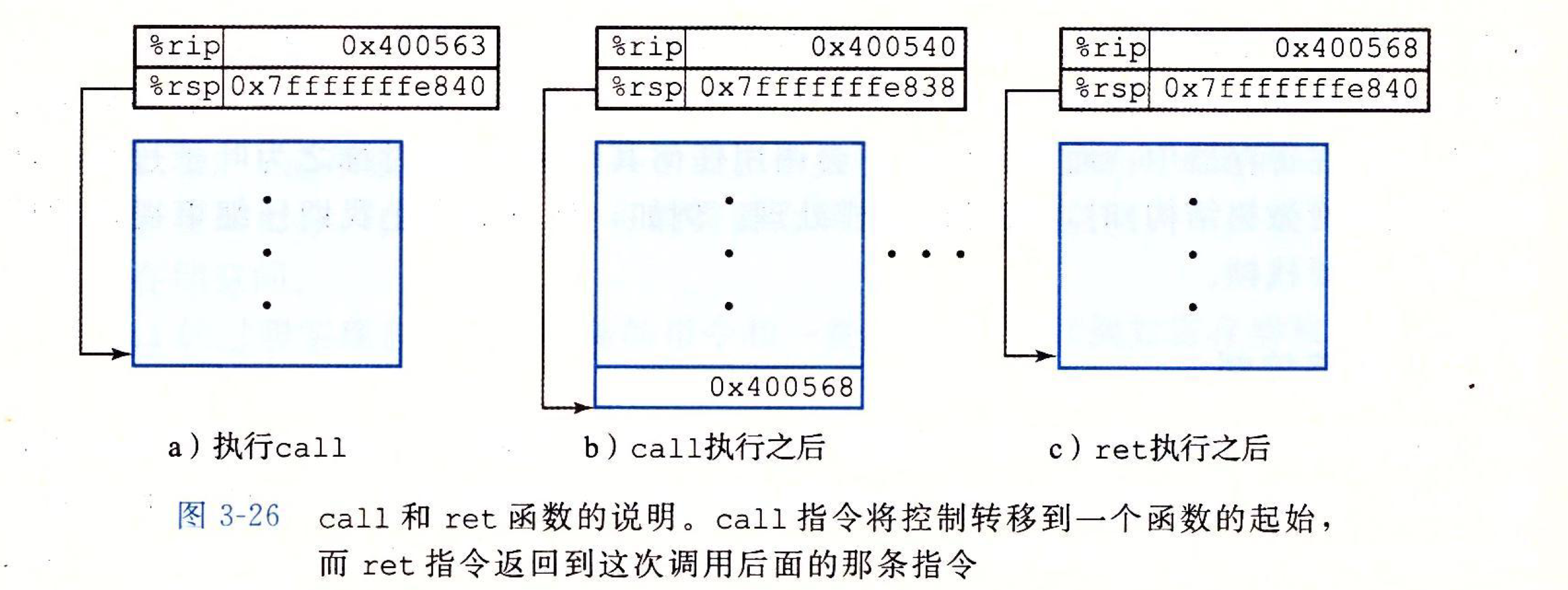
call指令 和 ret指令
call包括了两个部分: 一个是将程序计数器置为Q, 另一个是将返回地址压入栈中
ret则相反: 是弹出返回地址到程序计数器, 控制回到了P
数据传送
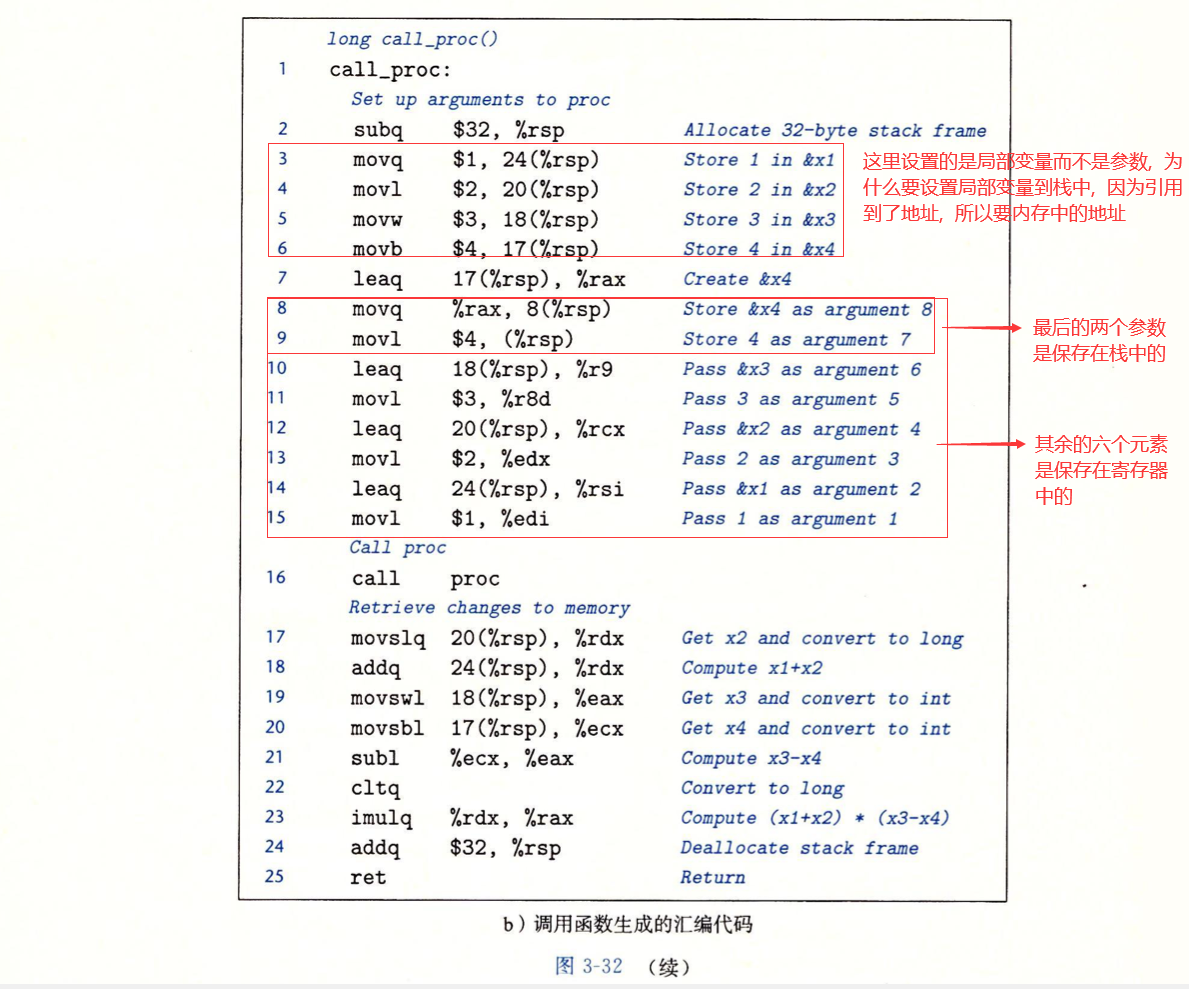
跟之前学的汇编语言(王爽老师的, 有点过时了)不一样(参数都是压入栈中), x86-64调用中的数据传送都是通过寄存器传递, 在大于6个参数的时候, 会把多出来的参数压入栈中
栈中的参数分配的空间也有规则: 数据大小要向 8 的倍数对齐
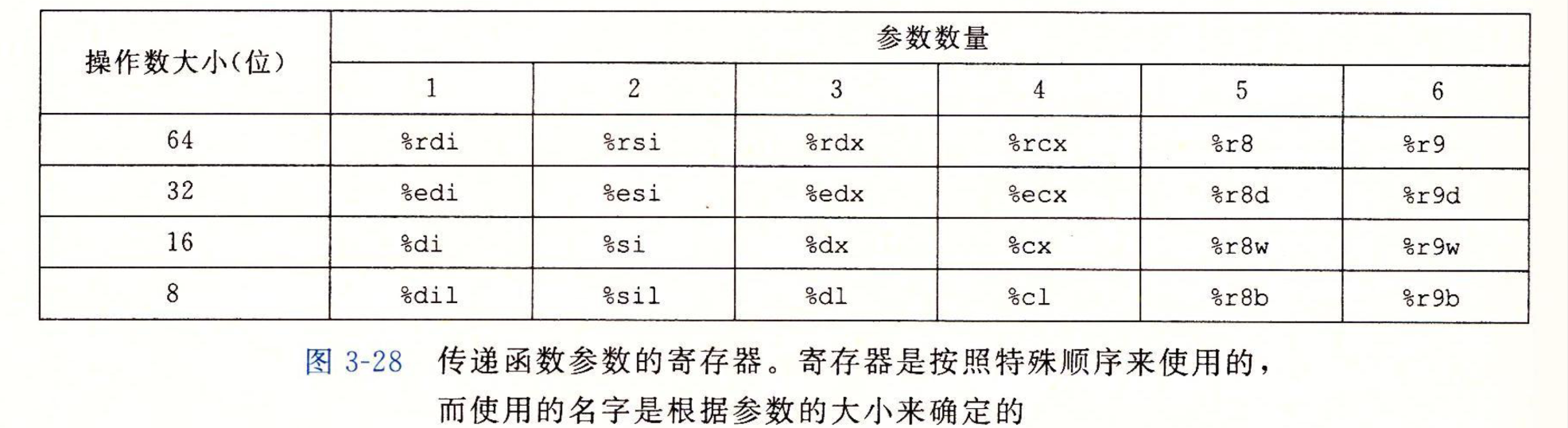
上面的那个对齐规则我不是很懂, 这个8 的倍数是8个位还是8个字节, 但是从书中的实例来看, 看<栈上的局部存储>的第二个实例, rsp也有加一的, 所以应该是8个位吧………
书中实例:

栈上的局部存储
虽然寄存器很多时候都能够完成很多局部变量的存储和运算, 但是有些时候还是要用到栈
这些情况包括:
- 寄存器不够存放所有的本地数据
- 对一个局部变量使用地址运算符” & ” , 因此必须为它生成一个内存地址
- 某些局部变量是数组或是结构, 因此必须能够通过数组或结果引用被访问到
书中实例:

这个实例时较复杂的那个
寄存器中的局部存储空间
被调用者保存寄存器
根据惯例, RBX 和 RBP 和 R12 ~ R15被划分为被调用者保存寄存器: 当P调用Q时, 被调用者Q必须保存这些寄存器的值, 保证它们的值在Q返回到P时, 与调用Q前一样.
保存方法有两种:
- 不改变这个寄存器的值
- 将寄存器的值压入栈中
调用者保存寄存器
除了RSP 和 被调用者保存寄存器, 其他的寄存器都归为调用者保存寄存器.
调用者保存可以这样理解: P调用Q, Q可以随意修改这些寄存器, 所以在调用前预先保存好这些数据时P(调用者)的责任
书中实例:

我认为这里的被调用者保存寄存器, 是因为在调用Q的时候不会改变才使用的, 上面的两个push并没有体现被调用者保存寄存器的特性, 只是在P的函数中防止rbp跟rbx之前的值被覆盖……这样讲的很晕
递归过程
书中实例也使用了被调用着保存寄存器 以及 栈的特性

数组分配和访问
数组再内存中的存放看的时数组元素的类型

C语言数组指针跟汇编的关系

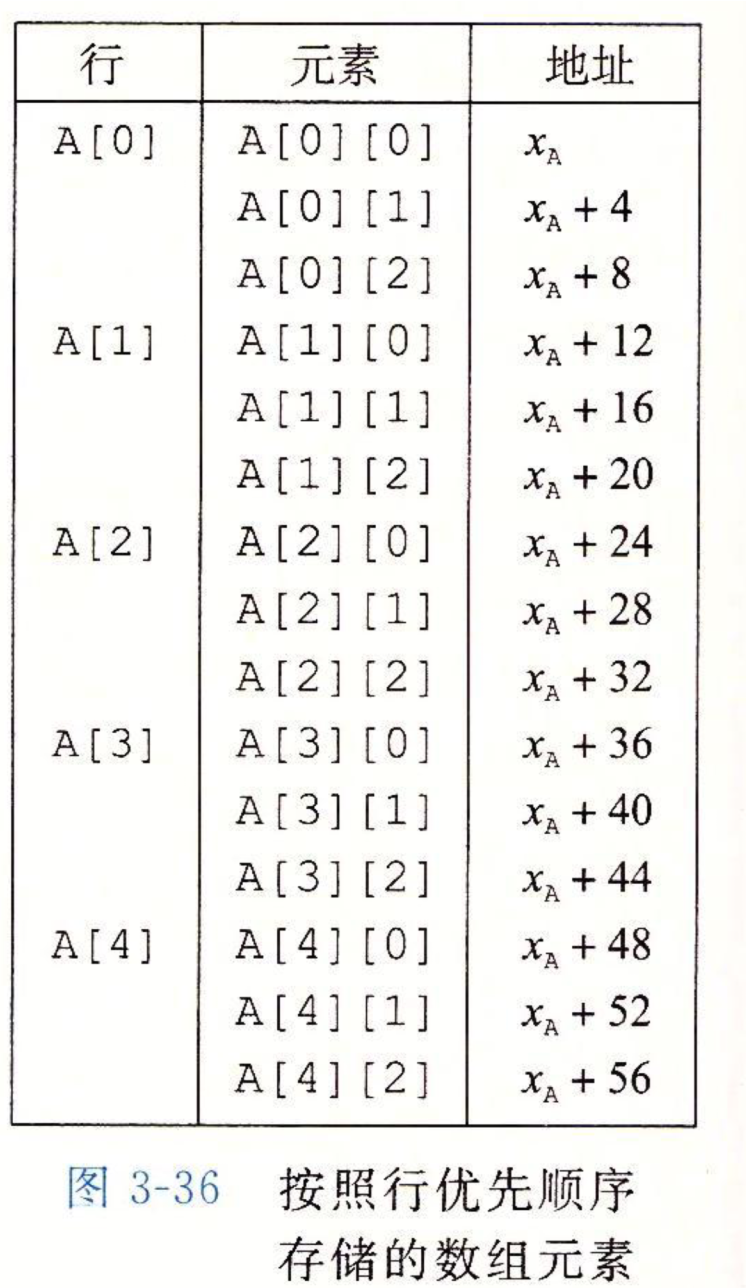
嵌套数组
遵循 ”行优先” 原则
变长数组
形式形如: int A [expr1] [expr2]
这样的表达式来指定任意元素, 但是在使用前, expr1跟expr2必须先计算得出

异质的结构数据
结构
将不同类型的对象聚合到一个对象中, 类似于数组的实现, 结构的所有部分都存放在一段连续的内存
注意:
- 传递参数时, 一般传递的时结构体的地址, 而不是每一个元素, 这样太麻烦了, 地址可以直接索引
结构体内存实例:

联合
机器级程序中将控制和数据结合起来
指针
关键的原则:
- 每个指针都对应一个类型
- 指针用 “ & ” 创建
- “ * ” 用于间接引用指针
- 数组与指针联系紧密
- 将指针从一种类型强制转换成另一种类型, 只改变它的类型, 而不改变它的值
- 指针也可以指向函数
内存越界引用和缓冲区溢出
C对数组引用不进行任何边界检查, 而局部变量和状态信息(返回值, 寄存器原来的值)都存在栈中, 当我们输入一些数据超出了原先在栈中计划的空间时, 这些数据就会覆盖(称为破坏更合适一些)我们的重要数据. 但我们需要返回等操作时, 就会发生错误
缓冲区溢出
通过输入一个字符串, 字符串中包含一些可执行代码的字节编码, 称为攻击代码, 或者是一个指向攻击代码的地址.